- these services are considered message brokers
- facilitate communication between different components of a distributed application by allowing for the asynchronous exchange of messages
- used to scale services - scalability for dummies
RabbitMQ (Traditional Q)
- take in messages → queue them → send to consumer
- handles moderate data volumes
- handles complex message routing
- typical use-cases: (1) job worker system, (2) message queue, (3) decoupling microservices
Kafka
- Kafka is essentially a stream processing system - designed to take in a stream of events, and send them off to a bunch of consumers
- features high throughput
- retains messages till TTL expires - consumed messages can be replayed after
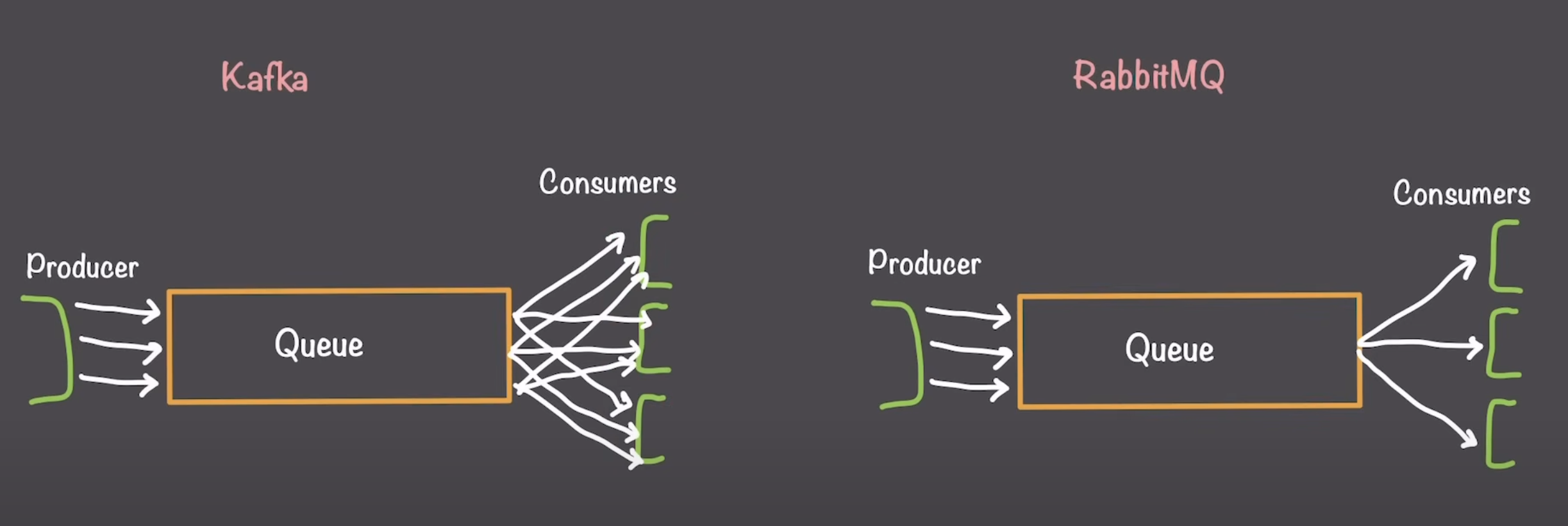
- fan out - each consumer connected to the queue will get one copy of each event
- typical use-cases: (1) streaming data processing, (2) event bus, (3) logging systems, (4) real time communication
Kafka vs. RabbitMQ
- Kafka is better suited for situations where we want to “fan out”
- eg. logs, data analysis, real-time updates (from the same event)
- RabbitMQ will handle each event individually (one processor for each event)
- with Kafka, the producer handles message routing - part of the reason why Kafka allows for such high throughput
- to scale, we can have multiple Kafka partitions, and hash the message on the producer side to determine which partition the message is sent to
- however, there is no control over where the messages go after they have been produced
- RabbitMQ uses “exchanges” - takes in all messages and routes them to different queues
- can also duplicate messages, to enable a “fan out” style
- consumers have control over what messages they are consuming
- summary: Kafka is better suited for messages that take uniform (and short) time to process, and for messages that “fan out”
- RabbitMQ is better suited for long running (unknown time) tasks, messages with complex routing, and sporadic / bursty data flow
What about ACKs? What if a Consumer Fails.
- with Kafka, we don’t use ACKs - we use offsets
- consumers fetch from Kafka, and then commits offset when they’re done
- ie. a consumer fails → offset is not committed → another consumer picks up
- while RabbitMQ uses ACKs
- consumers subscribes to Q for new data, and sends an ACK after processing
- ie. if a consumer fails → ACK is not received → after timeout, RabbitMQ sends to another consumer
- usually, services that use Kafka can tolerate messages being dropped to some extent